|
|
|
Entreprise JavaBeans
Summary
The original JavaBeans specification describes the standard behavior and properties of Java components that run primarily on the client side of a client/server system. The introduction of the Enterprise JavaBeans Specification Version 1.0 changes all that. Enterprise JavaBeans is a component architecture for creating scalable, multitier, distributed applications, and it makes possible the creation of dynamically-extensible application servers. This month, Mark presents a high-level view of Enterprise JavaBeans (EJB) technology, setting the stage for understanding the underlying components. He also talks about why EJB is so interesting to so many people. (4,200 words)
nterprise JavaBeans (EJB) has generated a great deal of excitement since the March 1998 announcement of the Enterprise JavaBeans Specification Version 1.0. Companies such as Oracle, Borland, Tandem, Symantec, Sybase, and Visigenic, among many others, have announced and/or delivered products that adhere to the EJB specification. This month, we'll take a high-level look at what exactly Enterprise JavaBeans is. We'll go over how EJB differs from the original JavaBeans component model, and discuss why EJB has generated such an enormous amount of interest.
But first, an advisory: we won't be looking at source code or how-to topics this month. This article isn't a tutorial; rather it's an architectural overview. EJB covers a lot of territory, and without first understanding the basic concepts involved, code snippets and programming tricks are meaningless. If there's interest on the part of JavaWorld's readers, future articles may cover the specifics of using the Enterprise JavaBeans API to create your own Enterprise JavaBeans.
In order to understand why EJB is so attractive to developers, we need some historical background. First, we'll look at the history of client/server systems, and at the current state of affairs. Then, we'll discuss the various parts of an EJB system: EJB components -- which live on an EJB container running inside an EJB server -- and EJB objects, which the client uses as a kind of "remote control" of EJB components. We'll go over the two types of EJBs: session and entity objects. You'll also read about home and remote interfaces, which create EJB instances and provide access to the EJB's business methods, respectively. By the end of the article, you'll have an idea of how extensible servers can be built using Enterprise JavaBeans. But first, a look back in time.
Client/server history
Ancient history
In the beginning, there was the mainframe computer. And it was good. (Or as good as it got, anyway.) The state of the art in information processing through the 1960s consisted primarily of big, expensive machines used by large organizations to support their daily business operations. Minicomputers and timesharing in the 1970s increased the accessibility of computing power, but information and processing were still centralized on individual machines. The first personal computers in the 1980s quickly cluttered the corporate landscape with thousands of tiny islands of information, all tirelessly churning out reports of variable quality, losing critical data when they crashed, and quickly becoming inconsistent with each other.Client/server to the rescue
The client/server architecture is one of the most common solutions to the conundrum of how to handle the need for both centralized data control and widespread data accessibility. In client/server systems, information is kept relatively centralized (or is partitioned and/or replicated among distributed servers), which facilitates control and consistency of data, while still providing access to the data users need.Client-server systems are now commonly composed of various numbers of tiers. The standard old mainframe or timesharing system, where the user interface runs on the same computer as the database and business applications, is known as single tier. Such systems are relatively easy to manage, and data consistency is simple because data is stored in only one place. Unfortunately, single-tier systems have limited scalability and are prone to availability hazards (if one computer's down, your whole business goes down), particularly if communication is involved.
The first client/server systems were two-tier, wherein the user interface ran on the client, and the database lived on the server. Such systems are still common. One garden-variety type of two-tier server performs most of the business logic on the client, updating shared data by sending streams of SQL to the server. This is a flexible solution, since the client/server conversation occurs at the level of the server's database language. In such a system, a properly designed client can be modified to reflect new business rules and conditions without modifying the server, as long as the server has access to the database schema (tables, views, and so forth) needed to perform the transactions. The server in such a two-tier system is called a database server, as shown below.

Figure 1. A database server
Database servers have some liabilities, though. Often the SQL for a particular business function (for example, adding an item to an order) is identical, with the exception of the data being updated or inserted, from call to call. A database server ends up parsing and reparsing nearly identical SQL for each business function. For example, all SQL statements for adding an item to an order are likely to be very similar, as are the SQL statements for finding a customer in the database. The time this parsing takes would be better spent actually processing data. (There are remedies to this problem, including SQL parse caches and stored procedures.) Another problem that arises is versioning the clients and the database at the same time: all machines must shut down for upgrades, and clients or servers that fall behind in their software version typically aren't usable until they're upgraded.
Application servers
An application server architecture (see the next image) is a popular alternative to a database server architecture because it solves some of the problems database servers have.

Figure 2. An application server
A database server environment usually executes business methods on the client, and uses the server mostly for persistence and enforcing data integrity. In an application server, business methods run on the server, and the client requests that the server execute these methods. In this scenario, the client and server typically will use a protocol that represents a conversation at the level of business transactions, instead of at the level of tables and rows. Such application servers often perform better than their database counterparts, but they still suffer from versioning problems.
Both database and application systems can be enhanced by adding additional tiers to the architecture. So-called three-tier systems place an intermediate component between the client and the server. An entire industry -- middleware -- has cropped up to address the liabilities of two-tier systems. A transaction-processing monitor, one type of middleware, receives streams of requests from many clients, and may balance the load between multiple servers, provide failover when a server fails, and manage transactions on a client's behalf. Other types of middleware provide communications protocol translation, consolidate requests and responses between clients and multiple heterogeneous servers (this is particularly popular in dealing with legacy systems in business process reengineering), and/or provide service metering and network traffic information.
Multiple tiers provide a flexibility and interoperability that has resulted in systems with more than these three layers of service. For example, n-tier systems are generalizations of three-tier systems, each layer of software providing a different level of service to the layers above and beneath it. The n-tier perspective considers the network to be a pool of distributed services, rather than simply the means for a client to accesses a single server.
As object-oriented languages and techniques have come into vogue, so have client/server systems increasingly moved toward object-orientation. CORBA (Common Object Request Broker Architecture) is an architecture that allows objects within applications -- even objects written in different languages -- to run on separate machines, depending on the needs of a given application. Applications written years ago can be packaged as CORBA services and interoperate with new systems. Enterprise JavaBeans, which is designed to be compatible with CORBA, is another entry into the object-oriented application-server ring.
The purpose of this article is not to provide a tutorial on client/server systems, but it was necessary to provide some background in order to define context. Now let's look at what EJB has to offer.
Enterprise JavaBeans and extensible application servers
Now that we've looked at a bit of history and have an understanding of what application servers are, let's look at Enterprise JavaBeans and see what it offers in that context.The basic idea behind Enterprise JavaBeans is to provide a framework for components that may be "plugged in" to a server, thereby extending that server's functionality. Enterprise JavaBeans is similar to the original JavaBeans only in that it uses some similar concepts. EJB technology is governed not by the JavaBeans Component Specification, but by the entirely different (and massive) Enterprise JavaBeans Specification. (See Resources for details on this spec.) The EJB Spec calls out the various players in the EJB client/server system, describes how EJB interoperates with the client and with existing systems, spells out EJB's compatibility with CORBA, and defines the responsibilities for the various components in the system.
Enterprise JavaBeans goals
The EJB Spec tries to meet several goals at once:
- EJB is designed to make it easy for developers to create applications, freeing them from low-level system details of managing transactions, threads, load balancing, and so on. Application developers can concentrate on business logic and leave the details of managing the data processing to the framework. For specialized applications, though, it's always possible to get "under the hood" and customize these lower-level services.
- The EJB Spec defines the major structures of the EJB framework, and then specifically defines the contracts between them. The responsibilities of the client, the server, and the individual components are all clearly spelled out. (We'll go over what these structures are in a moment.) A developer creating an Enterprise JavaBean component has a very different role from someone creating an EJB-compliant server, and the specification describes the responsibilities of each.
- EJB aims to be the standard way for client/server applications to be built in the Java language. Just as the original JavaBeans (or Delphi components, or whatever) from different vendors can be combined to produce a custom client, EJB server components from different vendors can be combined to produce a custom server. EJB components, being Java classes, will of course run in any EJB-compliant server without recompilation. This is a benefit that platform-specific solutions can't hope to offer.
- Finally, the EJB is compatible with and uses other Java APIs, can interoperate with non-Java apps, and is compatible with CORBA.
How an EJB client/server system works
To understand how an EJB client/server system operates, we need to understand the basic parts of an EJB system: the EJB component, the EJB container, and the EJB object.The Enterprise JavaBeans component
An Enterprise JavaBean is a component, just like a traditional JavaBean. Enterprise JavaBeans execute within an EJB container, which in turn executes within an EJB server. Any server that can host an EJB container and provide it with the necessary services can be an EJB server. (This means that many existing servers may be extended to be EJB servers, and in fact many vendors have achieved this, or have announced the intention to do so.)An EJB component is the type of EJB class most likely to be considered an "Enterprise JavaBean." It's a Java class, written by an EJB developer, that implements business logic. All the other classes in the EJB system either support client access to or provide services (like persistence, and so on) to EJB component classes.
The Enterprise JavaBeans container
The EJB container is where the EJB component "lives." The EJB container provides services such as transaction and resource management, versioning, scalability, mobility, persistence, and security to the EJB components it contains. Since the EJB container handles all of these functions, the EJB component developer can concentrate on business rules, and leave database manipulation and other such fine details to the container. For example, if a single EJB component decides that the current transaction should be aborted, it simply tells its container (in a manner defined by the EJB Spec, and the container is responsible for performing all rollbacks, or doing whatever is necessary to cancel a transaction in progress. Multiple EJB component instances typically exist inside a single EJB container.The EJB object and the remote interface
Client programs execute methods on remote EJBs by way of an EJB object. The EJB object implements the "remote interface" of the EJB component on the server. The remote interface represents the "business" methods of the EJB component. The remote interface does the actual, useful work of an EJB object, such as creating an order form or deferring a patient to a specialist. We'll discuss the remote interface in more detail below.EJB objects and EJB components are separate classes, though from the "outside" (that is, by looking at their interfaces), they look identical. This is because they both implement the same interface (the EJB component's remote interface), but they do very different things. An EJB component runs on the server in an EJB container and implements the business logic. The EJB object runs on the client and remotely executes the EJB component's methods.
Pretend for a moment that your VCR is an EJB component. The EJB object is then analogous to your remote control: both the VCR and the remote control have the same buttons on the front, but they perform different functions. Pushing the Rewind button on your VCR's remote control is equivalent to pushing the Rewind button on the VCR itself, even though it's the VCR -- and not the remote -- that actually rewinds a tape.
Similarly, call the
addEmployee()method on an EJB object, and it calls (indirectly, through the network) theaddEmployee()method on the remote EJB component. (Actually, the call goes through the EJB container, but that's an implementation detail.) In addition, Enterprise JavaBeans has the home interface (discussed below), which (to extend our analogy) helps you to find your "remote control," even if it's wedged down between the couch cushions.Where does the EJB object class come from, and how does it work?
The actual implementation of an EJB object is created by a code generation tool that comes with the EJB container. The EJB object's interface is the EJB component's remote interface. The EJB object (created by the container and tools associated with the container) and the EJB component (created by the EJB developer) implement the same remote interface. To the client, an EJB object looks just like an object from the application domain -- an order form, for example. But the EJB object is just a stand-in for the actual EJB, running on the server inside an EJB container. When the client calls a method on an EJB object, the EJB object method communicates with the remote EJB container, requesting that the same method be called, on the appropriate (remote) EJB, with the same arguments, on the client's behalf. See Figure 3 for a pictorial representation of this arrangement. This is the core concept behind how an EJB client/server system works.
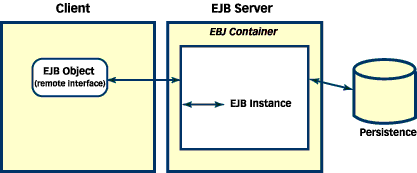
Figure 3. Enterprise JavaBeans in the client and the server
Types of Enterprise JavaBeans
There are two basic types of Enterprise JavaBeans: session beans and entity beans. These two types of beans play different roles in a distributed EJB application.A session bean is an EJB instance associated with a single client. Session beans typically are not persistent (although they can be), and may or may not participate in transactions. In particular, session objects generally don't survive server crashes. One example of a session object might be an EJB living inside a Web server that serves HTML pages to a user on a browser, and tracks that user's path through the site. When the user leaves the site, or after a specified idle time, the session object will be destroyed. Note that while this session object might be storing information to the database, its purpose is not to represent or update existing database contents; rather, it corresponds to a single client performing some actions on the server EJBs.
An entity bean represents information persistently stored in a database. Entity beans are associated with database transactions, and may provide data access to multiple users. Since the data that an entity bean represents is persistent, entity beans survive server crashes (this is because when the server comes back online, it can reconstruct the bean from the underlying data.) In relational terms, an entity bean might represent an underlying database row, or a single SELECT result row. In an object-oriented database (OODB), an entity bean may represent a single object, with its associated attributes and relationships. An example of an entity bean might be an
Employeeobject for a particular employee in a company's Human Resources database.An Enterprise JavaBeans client creates EJB objects on the server (we'll see how in just a moment) and manipulates them as if they were local objects. This makes developing EJB clients almost as easy as writing a client that runs locally: the developer simply creates, uses, and destroys objects, but these objects have counterparts executing on a server that do the actual work. Session beans manage information relating to a conversation between the client and the server, while entity beans represent and manipulate persistent application domain data. One way to conceptualize this is that entity beans replace the various sorts of queries used in a traditional two- or three-tier system, and session beans do everything else.
Every EJB has a unique identifier. For entity beans, this unique identifier forms the identity of the information. For example, an
EmployeeIDNumbermight uniquely identify anEmployeeobject. This is analogous to the concept of a primary key in a relational database system. A session bean's unique identifier is whatever distinguishes it from other beans of its type: it may be the host name and port number of a remote connection, or even just a randomly-generated key that the client uses to uniquely identify a given bean.Creating server-side beans: The home interface
So, a client program contacts a server and requests that the server create an Enterprise JavaBean to do data processing on its behalf. The server responds by creating the server-side object (the EJB component instance), and returning a proxy object (the EJB object) whose interface is the same as the EJB component's and whose implementation performs remote method invocations on the client's behalf. The client then uses the EJB object as if it were a local object, "never knowing" that a remote object is actually doing all the work.How does a client program create objects on a server? Operations involving the life cycle of server-side beans are the responsibility of the EJB container. The client program actually contacts the container and requests that a particular type of object be created, and the container responds with an EJB object that can be used to manipulate the new EJB component.
Each EJB component class has what is called a home interface, which defines the methods for creating, initializing, destroying, and (in the case of entity beans) finding EJB instances on the server. The home interface is a contract between an EJB component class and its container, which defines construction, destruction, and lookup of EJB instances.
An EJB home interface extends the interface
javax.ejb.EJBHome, which defines base-level functionality for a home interface. All methods in this interface must be Java RMI-compatible, meaning that every method must be usable by the java.rmi package. (Going into what "RMI-compatible" means is beyond the scope of this article.) The EJB home interface also defines one or morecreate()methods, whose names are allcreate, and whose signatures are distinct. The return value of these object create methods is the remote interface for the EJB. As stated above, the remote interface consists of the business methods the EJB provides. (We'll look at the remote interface shortly.)When a client wants to create a server-side bean, it uses the Java Naming and Directory Interface (JNDI) to locate the home interface for the class of bean it wants. The JNDI is a standard extension to the Java core that provides a global service to any Java environment, allowing Java programs to locate and use resources by name, to find out information about those resources, and to traverse structures of resources. EJB's use of JNDI is an example of EJB meeting its goal of compatibility with other Java APIs. We'll leave the nitty-gritty of how to use JNDI to locate a home interface to another column, since this article is simply an overview.
Once the client has the home interface for the EJB class it wants to create, it calls one of the
create()methods on the home interface to create a server-side object. The client-side home interface object does a remote method call to the EJB container on the server, which then creates the EJB component and returns an EJB object to the client. The client may then call the EJB object's methods, which are forwarded to the container. The container typically defers the implementation of the method to the EJB component, although it is also responsible for detecting some error conditions (such as nonexistence of the EJB component) and throwing appropriate exceptions.Entity beans also have additional home interface finder methods that locate individual persistent JavaBeans based on the bean's primary key. The home interface might be used, for example, to create an instance of a
ProductionFacilityobject, and then the finder method could be given theProductionFacilityCodenumber to locate the object representing a specific facility.The home interface also includes a method telling the container to remove a server-side instance of an EJB component. This method destroys the server-side instance. Trying to use the EJB object corresponding to a removed EJB causes an exception to be thrown.
Using server-side beans: The remote interface
Once the client has an EJB object, it can call that object's methods, which are implementations of the EJB component class's remote interface. An EJB remote interface extends the interfacejavax.ejb.EJBObject, and can define any method it wishes. The only restrictions are that the argument and return types for each method are RMI-compatible, and that each method must containjava.rmi.RemoteExceptionin itsthrowsclause. Furthermore, each method in an EJB remote interface must correspond exactly (that is, in name, argument number and type, return type, andthrowsclause) to a matching method in the Enterprise JavaBean component class the interface represents.Conclusion: Extensible application servers realized
The fundamental goal of a server component technology is this: how do you go about creating a server whose methods are extensible at runtime? How can someone, for example, buy an accounting package, drop it into a running server, and use the client software that came with the package to access the server functionality, all without even shutting the server down, much less recompiling it?The answer that Enterprise JavaBeans provides is to create the client in terms of remote interfaces. These remote interfaces are implemented on the client as remote method invocations of one sort or another, and the very same interface is implemented on the server side as domain functionality. The EJB server uses JNDI to publish the availability of these services. The client uses JNDI to locate a new class's home interface by name, and then uses the home interface to create objects with the remote interface that provides the service. This late-binding between available interfaces on a server and the interface names is what makes an EJB server runtime-extensible.
This introduction to Enterprise JavaBeans barely scratches the surface of this technology. We didn't even touch on issues such as scalability, replication, distributed processing, deployment, security, or transactions. We'll leave such topics for another day. With this basic understanding of the Enterprise JavaBeans framework, you're now ready to begin exploring how to create EJB applications in Java code.

Resources
- You can find out more about Enterprise JavaBeans in JavaWorld in Bryan Morgan's article "Enterprise JavaBeans: Coming soon to a server near you." Bryan discusses EJB distributed transactions and CORBA compatibility
http://www.javaworld.com/jw-06-1998/jw-06-distributed.html
- Enterprise JavaBeans was a hot topic at this year's JavaOne. Rich Kadel's JavaOne Today technical coverage of the topic can be found at
http://www.javaworld.com/javaone98/j1-98-ejb.html
- Try your hand at writing your own EJB by following Michael Shoffner's Step by Step column "Write a session EJB" featured in JavaWorld
http://www.javaworld.com/jw-07-1998/jw-07-step.html
- More introductory information about EJB, including a great description of the lifecycle of an EJB, appears in the NC World article "Enterprise JavaBeans: Industrial-strength Java"
http://www.ncworldmag.com/ncworld/ncw-01-1998/ncw-01-ejbeans.html
- Another NC World article covering EJB is "Bean Basics: Enterprise JavaBeans Fundamentals"
http://www.ncworldmag.com/ncworld/ncw-04-1998/ncw-04-ejbprog2.html
- Sun's home page for Enterprise JavaBeans technology can be found at
http://java.sun.com/products/ejb/index.html
- You can download the EJB Specification, all 181 pages of it, at
http://java.sun.com/products/ejb/docs.html
- Java Report Online has a great article by Richard Monson-Haefel that goes into more detail about how to use the EJB API. This article goes into the concepts of developer "roles" that are laid out by the EJB Specification, and provides a good backgrounder for anyone considering tackling the spec itself http://www.sigs.com/jro/features/9803/oldlayout/haefel.html
- Read Mark Johnson's previous JavaBeans columns
http://www.javaworld.com/topicalindex/jw-ti-beans.html
Advertisement: Support JavaWorld, click here!
HOME | FEATURED TUTORIALS | COLUMNS | NEWS & REVIEWS | FORUM | JW RESOURCES | ABOUT JW | FEEDBACK
